
Improved Baselines with Visual Instruction Tuning
Abstract
- 멀티모달 LLM에서 Visual Prompt tuning이 성능 향상에 도움이 됨.
- Vision-Language Connector의 도입이 중요함. (LLaVA 논문의 향후계획에서 Projection 방식 고도화 관련 내용임.)
- VQA 데이터를 추가하여 사전 학습에 사용함.
Introduction
- 대화형 시각추론에서는 LLaVA가 성능이 더 좋지만 전통적인 VQA 벤치마크에서는 InstructBLIP이 성능이 더 좋다.
- LLaVa를 기준으로 입력, 모델 아키텍처, 데이터의 관점에서 체계적인 연구를 시작함.
- Cross modal Connector와 instruction-following VQA 데이터셋을 추가하여 훈련을 진행했을때 더 나은 멀티모달 이해 능력을 가짐.
- Resampler를 사용하는 IntructBLIP과 Qwen-VL과는 다르게 LLaVA 1.5는 fully-connected projection layer를 사용함.
- 대규모 멀티모달 모델의 미해결 문제에 대해서 추가적인 연구를 진행함. (본 논문에서 소개하는 미해결 문제로는 Scaling to high-resolution image input , Compositional capabilities, Data efficiency, Data scaling 이다. )
Related Works
- Instruction-following large multimodal models (LMMs)
- 일반적인 대규모 멀티모달 LMM의 아키텍처는 Image Backbone, Pre trained LLM, Vision-Language Connector로 구성됨.
- LMM에서 Visual resampler인 Qformer가 사용되기도 함.
- Multimodal instruction-following data
- NLP에서는 instruction-following data의 품질이 결과로 나온 명령어 수행 모델의 능력에 크게 영향을 미침.
- InstructionBLIP에서 VQA 데이터셋을 instruction-following data로 사용하였다. 이는 모델이 VQA 데이터셋에 과적합이 되어버리는 문제점이 발생함. 따라서, VQA 데이터셋을 대화형으로 변환하기 위해서 LLaVA의 Generation 방식을 빌려서 대화형 데이터로 생성함.
- FLAN 관련 논문에서는 Instruction tuning을 위해 academic language tasks를 추가하는 것이 일반화 능력을 향상킨다고 함. 이를 바탕으로 본 논문에서 academic tasks와 자연스러운 대화 간의 성능 균형을 맞추지 못하는 것을 조사함.
Approach
- Preliminaries
- LLaVA의 문제점으로는 단답형 응답(예: 단어 하나)을 필요로 하는 academic tasks 벤치마크에서 부족하여 해당 테스크에 대한 성능이 좋지않다. 예를들면 예/아니오 질문에 대해 '예'라고만 대답하는 경향이 있다.
- 하지만, InstructBLIP은 academic tasks 성능이 좋다. 그 이유로는 VQA 데이터셋을 사용해 Q-former를 사전학습하여 academic language tasks에 대한 성능은 좋다. 하지만, Conversation task에서는 성능이 별로 좋지 않다.
(InstructBLIP을 기반으로 성능에 대한 비교를 진행한다.)

- Response Format Prompting
- InstructBLIP이 단답형으로 답을 계속하는 첫 번째 이유로는 Answer에 대한 프롬프트가 모호하다. 즉, 원하는 출력형식이 정해져있지 않아서 단답형 데이터에 과대적합되어 해당 문제가 발생함.
- 두 번째 이유로는 LLM은 Frozen하고 Q-former만 미세 조정하여서 모델 용량에 비해서 이미지에 대한 단답 or 장문으로 답을 생성하는데 한계가 존재함.
- LLaVA 1.5는 단답형 대답을 잘 처리하고 위에 BLIP 문제를 해결하기 위해서 출력형식을 명확하게 지시하는 Single response formatting prompt를 사용하여 fine tuning 한다.

- Single response formatting prompt를 통해서 사용자가 원하는 특정 형식으로 답변을 제공가능하다.
- Fine tunong 단계에서 academic tasks와 관련된 벤치마크 데이터 추가해서 훈련했을 때 성능이 상당히 오름.
- Scaling the Data and Model
- MLP vision-language connector
Linear projection에서 MLP를 사용한 Projection으로 변경하면서 self supervised learning 및 멀티모달 성능이 향상되었음. - Academic task oriented data
InstructBLIP에서 사용된 academic data를 추가해 훈련했을 때, InstructBLIP의 성능을 이미 뛰어 넘었음.
- MLP vision-language connector

- Additional scaling
- 이미지를 더 세세하게 분석이 가능하도록 Image encoder를 CLIP-ViT-L-336px로 바꿈.
- GQA, ShareGPT, LLM 모델크기를 확장시켜 성능을 크게 개선함.
- Computational cost
- 동일한 사전학습 데이터를 사용하고 입력 해상도를 크게 늘려서 사전 훈련시간으로는 A100 8개 기준 6시간, 시각적 지시 튜닝에 20시간이 소요됨. (Q. 위에 데이터 추가한 것은 Instruction following data 느낌으로 fine tuning 되는 것인가? )
- Scaling to Higher Resolutions
LLaVA에서 이미지의 해상도를 늘리면 성능이 더 좋아지는 것을 확인함. 따라서, 해상도를 늘리고자 하는 연구가 진행됨. 하지만, CLIP에서는 3362로 해상도가 제한됨. 따라서, 본 논문에서 제시한 것은 LLaVA-1.5-HD임.
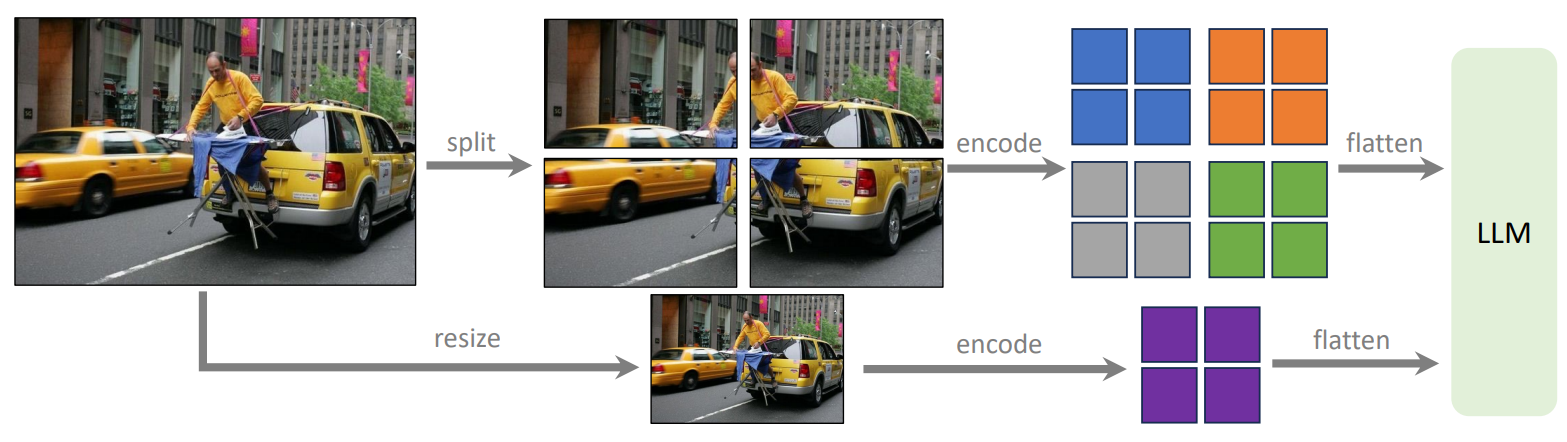
- LLaVA-1.5-HD
해상도가 큰 이미지를 Patch로 쪼개서 각 Patch의 특징벡터를 추출함. 그리고 큰 해상도의 이미지를 CLIP의 3362에 들어갈 수 있는 크기로 줄인 뒤 전체 이미지에 대한 특징벡터를 추출함. 이후, 각 Patch 특징벡터 + 사이즈가 조정된 전체 이미지의 특징벡터를 LLM의 입력으로 넣음.
- LLaVA-1.5-HD
Empirical Evaluation
총 12개의 벤치마크를 통해 평가함. 12개의 벤치마크에서 전체적으로 SOTA 달성함.
- VQA-v2와 GQA을 사용하여 Open world 단답형 시각적 인식 성능을 평가함.
- VizWiz을 사용하여 제로샷 성능을 평가함.
- TextVQA 을 사용하여 모델의 텍스트 이해 성능을 평가함.
- MME-Perception 예/아니오를 통해 시각적 인식 성능을 평가함.
- POPE은 COCO 이미지에 대한 샘플 하위집합(랜덤, 기본, 적대적) 예시를 줘서 모델이 예측하게 하여 hallucination 정도를 평가함.
- MMBench 모델의 답변 강건성을 평가함.
- MMBench-CN은 MMBench를 중국어로 번역한 것임.
- SEED-Bench 이미지와 비디오에 대해 객관식으로 모델의 성능을 평가함.
- LLaVA-Bench-in-the-Wild와 MM-Vet 다양한 과제에서 시각적 대화에 참여하는 모델의 능력을 평가하며 GPT-4 평가를 통해 응답의 정확성과 유용성을 평가함.
LLaVA-1.5의 경쟁력
- LLaVA-1.5 (7B 모델조차도)는 수십억 개의 학습 가능한 파라미터를 가진 80B IDEFICS를 능가함.
- 이는 멀티모달 지시 수행 능력 측면에서 비전 샘플러와 추가 대규모 사전 훈련의 필요성이 인심됨.
Global context
- Patch에 대한 특징벡터만 주는 것이 아닌 resize를 통해 전체 이미지의 특징벡터를 함께 주니깐 성능이 올라감.

Emerging Properties
- Format instruction generalization
LLaVA에서 몇 가지의 instruction format을 확장했다. 이를 통해 VizWiz의 Unanswerable 성능이 11.1% -> 67.8%로 향상됨. ( VizWiz는 주어진 이미지와 텍스트만으로 질문에 답하기가 어려울 경우에 Unanswerable이라는 레이블이 따로 존재함.)


- Multilingual multimodal capability
다국어 관련 fine tuning을 진행하지 않았음에도 다국어 지시를 따를 수 있는 능력을 가짐. 이는 ShareGPT에서 Multilingual Instruction 때문이라 소개함.
Ablation on LLM Choices
LLaMA 기반(Vicuna-v1.1, Vicuna-v1.3)과 LLaMA2 기반(Vicuna-v1.5, LLaMA-2-Chat)에 대해서 평가를 진행함. 이때, 전반적으로 LLaMA보다 LLaMA2 성능이 더 좋았고 LLaMA2 기반에서는 Vicuna-v1.5가 일반적인 성능이 더 좋았다.
이를 통해 Frozen된 LLM의 능력은 Instruction tuning된 모델의 성능에 큰 영향을 미친다는 것을 의미함. 즉, LLM의 초기 성능이 후속 모델의 멀티모달 능력에 중요한 역할을 한다는 것을 의미함.
Open Problems in LMMs
- Data Efficiency
LLaVA 1.5는 LLaVA와 비교하였을 때 훈련 시간이 2배가 된다. 이는 훈련되는 데이터 양의 차이때문에 발생한다. 따라서, 샘플링을 통해서 성능의 변화를 알아보고자 한다.- 전체 데이터에 50% 샘플링을 진행했을 때 거의 전체 데이터셋의 98% 성능을 가져옴.
- 특정 데이터 셋에서는 전체 데이터에 30% 샘플링만 진행해도 성능이 전체 데이터셋으로 훈련한 것과 유사함.
- 이러한 결과는 멀티모달 모델에서도 less-is-more의 가능성을 보여줌.
- Rethinking Hallucination in LMMs
Hallucination 은 LLM과 LMM에서 해결해야 할 중요한 문제이다. 이는 모델이 실제로 존재하지 않는 정보를 생성하거나 잘못된 정보를 제공하는 현상을 말한다.
- 모델의 입력 해상도를 4482와 같이 더 높은 해상도로 확장할 때 이러한 환각이 크게 감소한다는 것을 발견함.
- 더 세밀한 데이터(해상도가 큰)를 모델에게 제공하고 제공된 데이터에 맞춰서 모델이 잘 처리할 때 Hallucination을 완화하는 능력을 보였음을 미뤄봤을 때, 모델 능력과 데이터의 균형점을 맞춰 같이 발전하는 것이 중요함.
- Compositional Capabilities
- LLaVA-1.5는 특정 작업에 대해 훈련된 모델이 특정 작업에 대한 훈련 없이도 좋은 성능을 보여줌
- 이는 모델이 개별 작업에서 학습한 능력을 조합하여 새로운 작업에 적용할 수 있음을 의미함.
- 하지만, 특정 능력의 조합을 요구하는 일부 작업에서는 여전히 이상적인 성능을 달성하기 어려움.
- 예를 들어, VQA에서 특정 객체의 속성을 올바르게 답변할 수 있지만 전체 이미지의 상세 설명에서 그 객체 속성을 정확하게 묘사하는 것을 보장하지 않음.
Conclusion
Vision-Language Connector, Visual Instruction tuning 그리고 이미지 데이터 해상도 확장을 통해 LMM의 성능이 효율적으로 증가하는 것을 보여줌. 추가로, 미해결 문제에 대해서도 언급을 하며 향후 LMM 연구 방향도 제시해줌.
Appendix
- Instruction-following Data Mixture of LLaVA-1.5

- Response Format Prompts
다양한 Prompt format에서 LLaVA 1.5의 성능을 보여줌.



- 한계점
- LaVA-1.5는 전체 이미지 패치를 사용하여 훈련 반복 시간이 길어지는 문제점이 존재함. 따라서, 효율적인 시각적 리샘플러 개발의 필요성
- LLaVA-1.5는 다중 이미지를 처리할 수 없다. 이는 그러한 Instruction following data의 부족과 컨텍스트 길이의 제한 때문이다. (GPT-4를 사용해서 Instruction following data를 만든다면 가능한가?)
- LLaVA-1.5는 복잡한 지시를 따르는 능력을 보여주지만 특정 도메인에서 문제 해결 능력이 제한적임.
- LLaVA-1.5는 환각의 발생 빈도가 크게 줄었음에도 불구하고, 환각을 완전히 피하지는 못함. (의료분야 도입은 주의해야함)
- BLIP-2 (Q-former 관련)
- 기존의 Computaion Cost가 매우 커서 Image encoder과 LLM을 Frozen해서 모델을 개발하고자 함.
- 이때, 각각의 백본은 단일 모달리티에서 훈련된 것이라 Image-Text Alignment가 필요함.
- 이를 위해서 새로운 방법으로 Q-former를 제시하여 Modality Gap을 줄임.
'Paper Review > LLM' 카테고리의 다른 글
| [Paper Review] Visual Instruction Tuning (0) | 2024.06.04 |
|---|